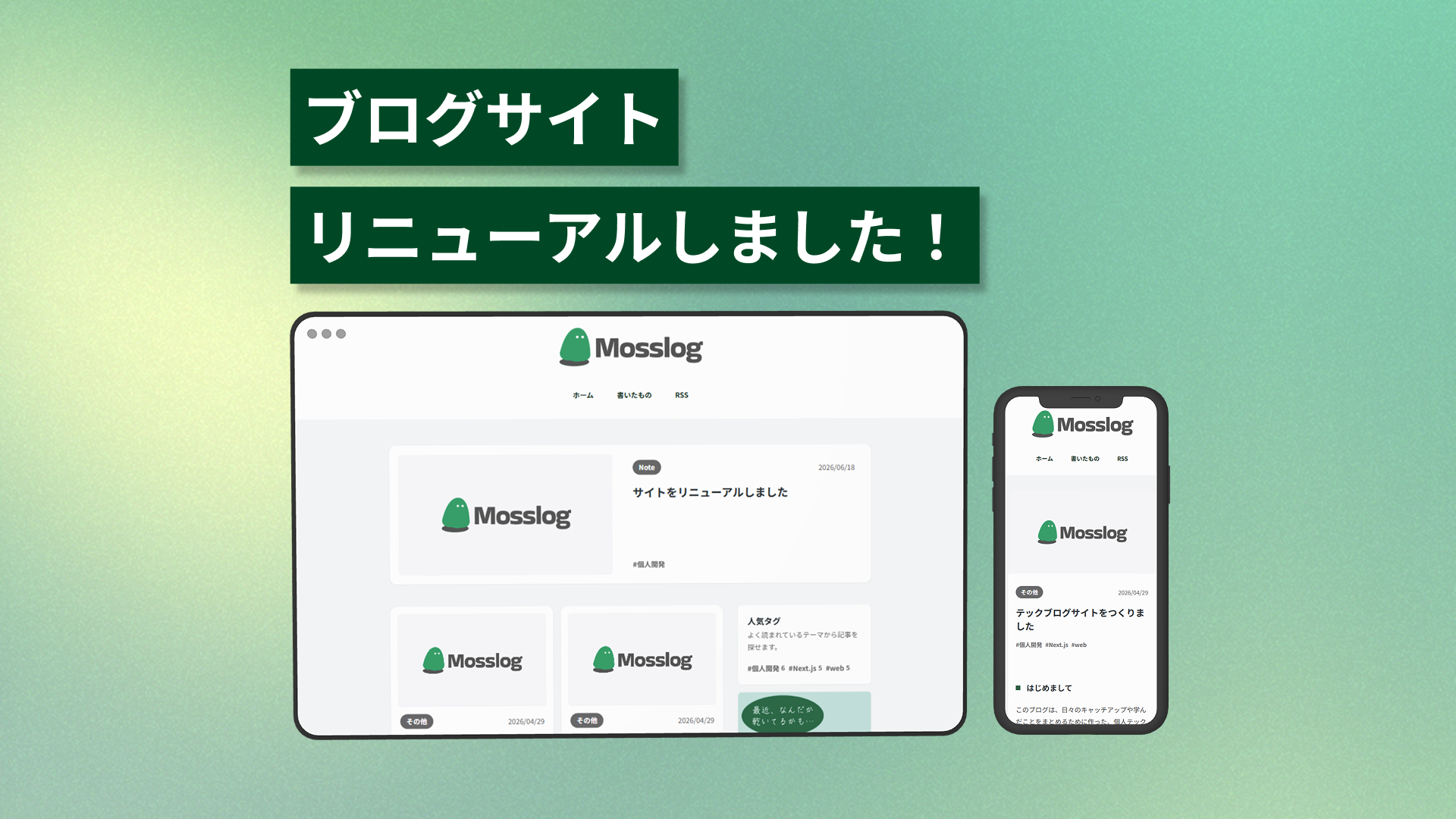
はじめに
前回の記事で、技術選定の理由と経緯について書きました。 今回は、実際の開発で遭遇した課題と、それをどう解決したかをまとめます。 開発で遭遇する課題は避けられないものですが、解決プロセスを記録しておくことで、同じような課題に遭遇した人への参考になればと思います。
この記事では、以下の6つの課題について、問題の概要、解決プロセス、解決方法を詳しく書いていきます。
1. Next.js 15のApp Routerとの格闘: Server ComponentsとClient Componentsの使い分け
2. Cloudflare WorkersでのEdge Runtime制約: Node.js APIの非互換性
3. D1データベースのクエリ最適化: パフォーマンス問題の解決
4. マークダウンのXSS対策: セキュリティと機能の両立
5. 画像アップロードの実装: Presigned URLの活用
6. JWT認証の実装: Cloudflare Accessとの統合
課題1: Next.js 15のApp Routerとの格闘
Next.js 15のApp Routerを使い始めたとき、Server ComponentsとClient Componentsの使い分けで何度もハマりました。 最初は、すべてのコンポーネントをServer Componentsとして書いていました。 しかし、以下のような機能を実装しようとすると、エラーが発生しました。
- インタラクティブなUI: ボタンクリックやフォーム入力など、ユーザーインタラクションが必要な機能
- ブラウザAPIの使用:
localStoragewindowオブジェクトなど、ブラウザ専用のAPI- 状態管理:
useStateuseEffectなどのReact Hooks
エラーメッセージはuse clientディレクティブが必要ですというものでした。 最初は、このエラーの意味がよく分からず、どこ"use client"を追加すればいいのか迷いました。
解決プロセス
ドキュメントの深掘り Next.jsの公式ドキュメントを読んで、Server ComponentsとClient Componentsの違いを理解しました。 Server Components
- サーバー側でレンダリングされる
- データベースへのアクセスや、サーバー側の処理が可能
- クライアント側のJavaScriptバンドルに含まれない(パフォーマンス向上) Client Components
- クライアント側でレンダリングされる
- インタラクティブなUIや、ブラウザAPIが使える
-
"use client"ディレクティブが必要
解決方法
コンポーネントの分割戦略 解決方法として、コンポーネントを分割しました。
- Server Components: データ取得や、静的なコンテンツの表示
- Client Components: インタラクティブなUIや、状態管理が必要な部分
例えば、記事一覧ページでは
// Server Component(データ取得)
export default async function ArticlesPage() {
const articles = await getArticles();
return <ArticleList articles={articles} />;
}
// Client Component(インタラクティブなUI)
"use client";
export function ArticleList({ articles }) {
const [filter, setFilter] = useState("");
// ...
} このように、データ取得はServer Componentで行い、インタラクティブな部分はClient Componentに分けました。
状態管理の見直し
状態管理が必要な場合、以下の方針を取りました
- サーバー側の状態: Server Componentsで取得したデータは、propsとしてClient Componentsに渡す
- クライアント側の状態:
useStateuseEffectを使う場合は、Client Componentにする
学んだこと
Next.js 15のApp Routerでは、デフォルトでServer Componentsという点が重要です。 慣れてくると、Server ComponentsとClient Componentsを適切に使い分けることで、パフォーマンスと開発体験の両方を向上させられることが分かりました。
課題2: Cloudflare WorkersでのEdge Runtime制約
Cloudflare Workersは、Edge Runtimeで動作します。 Edge Runtimeは、Node.jsのランタイムとは異なり、一部のNode.js APIが使えません。 最初は、Node.jsで動くパッケージをそのまま使おうとして、エラーが発生しました。 特に、reading-timeパッケージを使おうとしたとき、Node.js専用のAPIを使っているため、Edge Runtimeで動作しませんでした。
エラーメッセージはprocess is not defined」やfs is not defined」といったものでした。これらは、Node.jsのグローバルオブジェクトですが、Edge Runtimeでは使えません。
解決プロセス
エラーログの分析 エラーログを読むと、どのAPIが使えないかが分かりました。Cloudflare Workersのドキュメントを確認すると、Edge Runtimeで使えるAPIと使えないAPIのリストがありました。 Cloudflare Workersの公式ドキュメントを読んで、Edge Runtimeの制約を理解しました。
- 使えるAPI: Web標準のAPI
fetchURLTextEncoderなど)- 使えないAPI: Node.js専用のAPI
fspathprocessなど)
代替実装の検討
reading-timeパッケージの代わりに、独自実装を作ることにしました。 読了時間の計算は、文字数を数えて、読書速度で割るだけなので、シンプルな実装で対応できます。
解決方法
reading-timeパッケージの独自実装 記事を表示するコンポーネントに、読了時間を計算するメソッドを追加しました。
static calculateReadingTime(content: string): number {
// マークダウン記号やHTMLタグを除去して文字数をカウント
const text = content .replace(/```[\s\S]*?```/g, "") // コードブロックを除去
.replace([^]/g, "") // インラインコードを除去
.replace(/\[([^\]]+)\]\([^)]+\)/g, "$1") // リンクのテキストのみ抽出
.replace(/[#*_~[\]()]/g, "") // マークダウン記号を除去
.replace(/<[^>]+>/g, "") // HTMLタグを除去
.replace(/\s+/g, " ") // 連続する空白を1つに
.trim();
const characterCount = text.length; // 日本語の場合は200文字/分を基準とする
const minutes = Math.ceil(characterCount / 200);
return Math.max(1, minutes); // 最低1分
} この実装は、Web標準のAPIのみを使っているため、Edge Runtimeで動作します。 Edge Runtimeでは、Web標準のAPIを使うことが重要です。
例えば、
- 文字列処理:
String.prototype.replace()String.prototype.trim()- 正規表現:
RegExpオブジェクト- 数学関数:
Math.ceil()Math.max()
これらは、すべてWeb標準のAPIなので、Edge Runtimeで問題なく動作します。
学んだこと
Edge Runtimeの制約は、最初は不便に感じましたが、Web標準のAPIを使うことで、よりポータブルなコードを書けることが分かりました。また、Node.js専用のパッケージに依存しないことで、コードの見通しも良くなりました。
課題3: D1データベースのクエリ最適化
記事一覧ページを実装したとき、記事の取得が遅いという問題が発生しました。 特に、記事数が増えてきたときに、ページの読み込み時間が長くなりました。
最初は、単純SELECT FROM articles ORDER BY updated_at DESCというクエリを実行していました。しかし、記事数が増えると、このクエリの実行時間が長くなりました。
解決プロセス
パフォーマンス計測 まず、どのクエリが遅いのかを特定するため、パフォーマンス計測を行いました。D1では、クエリの実行時間をログで確認できます。
ボトルネックの特定
ボトルネックを特定すると、以下の問題が分かりました。
- インデックス未設定:
updated_atカラムにインデックスがなかった- 不要なデータ取得: すべてのカラムを取得していた
解決方法
インデックスの追加 マイグレーションファイルに、以下のインデックスを追加しました。 `
CREATE INDEX idx_articles_updated_at ON articles(updated_at DESC);
CREATE INDEX idx_articles_draft ON articles(draft);
CREATE INDEX idx_articles_draft_updated ON articles(draft, updated_at DESC);
CREATE INDEX idx_articles_created_at ON articles(created_at DESC); これによりORDER BY updated_at DESCのクエリが高速化されました。
クエリの見直し
クエリを見直して、必要なカラムのみを取得するようにしました。
また、ページネーションを実装して、一度に取得する記事数を制限しました。 ページネーションを実装することで、一度に取得する記事数を制限しました。これにより、クエリの実行時間が短縮されました。
学んだこと
データベースのクエリ最適化では、インデックスの重要性を実感しました。適切なインデックスを設定することで、クエリの実行時間を大幅に短縮できます。また、ページネーションを実装することで、大量のデータを扱う場合でも、パフォーマンスを維持できます。
課題4: マークダウンのXSS対策
マークダウンをHTMLに変換する際、XSS(Cross-Site Scripting)攻撃のリスクがあります。マークダウンに悪意のあるHTMLやJavaScriptが含まれている場合、そのままHTMLに変換すると、セキュリティ上の問題が発生します。
最初は、マークダウンをそのままHTMLに変換していましたが、セキュリティの観点から、サニタイズ(無害化)が必要だと気づきました。
解決プロセス
セキュリティのベストプラクティスを調査して、マークダウンのサニタイズ方法を調べました。一般的には、ホワイトリスト方式で、許可された要素や属性のみを残す方法が推奨されています。
サニタイズライブラリの比較
サニタイズライブラリを比較してrehype-sanitizeを選びました。理由は以下の通りです。
- rehypeエコシステム: 既
rehypeを使っていたため、統合しやすい- カスタマイズ性: カスタムスキーマで、必要な要素や属性を許可できる
- メンテナンス: 活発にメンテナンスされている
カスタムスキーマの設計
シンタックスハイライトやコードコピーボタンなどの機能を維持するため、カスタムスキーマを設計しました。デフォルトのスキーマでは、これらの機能に必要な要素や属性が削除されてしまうためです。
解決方法
markdown.tsにrehype-sanitizeを追加しました。処理の順序が重要で、シンタックスハイライトやコードコピーボタンを追加した後にサニタイズする必要があります。
const result = await unified() .use(remarkParse) .use(remarkGfm) .use(remarkRehype, { allowDangerousHtml: true }) .use(rehypeRaw) .use(rehypeSlug) .use(rehypeLinkIcon) .use(rehypeHighlight) // シンタックスハイライト
.use(rehypeCodeCopy) // コードコピーボタン
.use(rehypeSanitize, sanitizeSchema) // サニタイズは最後
.use(rehypeStringify)
.process(markdown); 許可リストの設定 カスタムスキーマで、以下の要素や属性を許可しました
- シンタックスハイライト用:
hljs-*クラスlanguage-*クラス- コードコピーボタン用:
button要素data-code属性- リンクアイコン用:
svg要素path要素- 目次リンク用: 見出し要素
id属性
これにより、必要な機能を維持しながら、XSS攻撃を防ぐことができました。
学んだこと
セキュリティと機能の両立は、バランスが重要です。過度にサニタイズすると、必要な機能が動かなくなる可能性があります。一方で、サニタイズが不十分だと、セキュリティ上の問題が発生します。 カスタムスキーマを設計することで、必要な要素や属性のみを許可し、セキュリティと機能の両立を実現できました。
課題5: 画像アップロードの実装
記事にアイキャッチ画像を設定する機能を実装する際、画像のアップロード方法で迷いました。 最初は、サーバーを経由してアップロードしようと考えましたが、以下の問題がありました。
- パフォーマンス: サーバーを経由すると、アップロードが遅くなる
- サーバーの負荷: 大きな画像ファイルをサーバーで処理すると、負荷がかかる
- スケーラビリティ: トラフィックが増えると、サーバーのリソースが不足する可能性がある
解決プロセス
AWS S3のドキュメント参照 Presigned URLという仕組みがあることを知りました。Presigned URLは、一時的なURLを生成して、クライアントから直接オブジェクトストレージにアップロードできる方式です。
R2のAPIドキュメント確認
Cloudflare R2は、AWS S3と互換のAPIを持っているため、S3のPresigned URLの仕組みがそのまま使えます。R2のドキュメントを確認して、Presigned URLの生成方法を調べました。
エラーケースの洗い出し
エラーケースを洗い出して、以下のケースに対応する必要があることが分かりました。
- ファイルタイプの検証: 画像ファイル以外をアップロードさせない
- ファイルサイズの制限: 大きすぎるファイルをアップロードさせない
- アップロード失敗時の処理: ネットワークエラーなどの場合の処理
解決方法
Presigned URLを生成するAPIエンドポイントを作成しました@aws-sdk/s3-request-presignerを使って、Presigned URLを生成します。
import { S3Client, PutObjectCommand } from "@aws-sdk/client-s3";
import { getSignedUrl } from "@aws-sdk/s3-request-presigner";
const s3Client = new S3Client({
region: "auto", endpoint: r2Endpoint, credentials: { accessKeyId: r2AccessKeyId, secretAccessKey: r2SecretAccessKey, }, });
const command = new PutObjectCommand({ Bucket: r2BucketName, Key: imageKey, ContentType: fileType, });
const presignedUrl = await getSignedUrl(s3Client, command, { expiresIn: 3600, // 1時間
}); 画像削除フローの実装
画像を削除する際、データベースからURLを削除するだけでなく、R2からも実際のファイルを削除する必要があります。削除APIエンドポイントを作成して、R2からも削除する処理を実装しました。
学んだこと
Presigned URLを使うことで、サーバーの負荷を減らしながら、セキュアにアップロードできることが分かりました。また、S3互換のAPIを使うことで、既存の知識やライブラリを活かせる点も良かったです。
課題6: JWT認証の実装
管理画面へのアクセスを制限するため、JWT認証を実装する必要がありました。 Cloudflare Accessを使うと、JWTトークンが自動的に発行されますが、Cloudflare Workers側でJWTトークンを検証する必要があります。 最初は、JWTの検証方法がよく分からず、どのライブラリを使えばいいのか迷いました。
解決プロセス
JWT仕様の理解 JWTの仕様を理解して、トークンの構造や検証方法を学びました。JWTは、ヘッダー、ペイロード、署名の3つの部分から構成されています。
joseライブラリの調査
JWT検証ライブラリを調査してjoseを選びました。理由は以下の通りです。
- Edge Runtime対応: Edge Runtimeで動作する
- JWKS対応: JWKS(JSON Web Key Set)を使って署名検証ができる
- TypeScript対応: TypeScriptの型定義が充実している
解決方法
joseライブラリでの検証実装 utils/auth.tsに、JWT検証の処理を実装しました。
import { jwtVerify, createRemoteJWKSet } from "jose";
const JWKS = createRemoteJWKSet( new URL("https://your-team.cloudflareaccess.com/cdn-cgi/access/certs") );
export async function verifyJWT(token: string) { try { const { payload } = await jwtVerify(token, JWKS, { issuer: https://your-team.cloudflareaccess.com, audience: "your-audience", });
return payload; } catch (error) {
return null;
} } 学んだこと
JWT認証の実装では、JWKSを使った署名検証が重要だと分かりました。JWKSを使うことで、公開鍵を自動的に取得して検証できるため、鍵の管理が楽になります。
今後の課題
現時点で、以下の課題が残っています。
- 関連記事の表示: データ構造は準備済みだが、表示機能は未実装
- 全文検索(FTS): 現時点では、タイトルとタグでの検索のみ
- 画像最適化: R2 Image Transformationの活用を検討中
今後の改善予定
今後の改善予定として、以下の点を検討しています。
- パフォーマンス最適化: 記事数が増えたときのパフォーマンス改善
- 機能追加: コメント機能や、いいね機能などの追加
- UI/UX改善: ユーザー体験の向上
終わりに
この記事では、開発で遭遇した課題と、その解決方法についてまとめました。開発で遭遇する課題は避けられないものですが、解決プロセスを記録しておくことで、同じような課題に遭遇した人への参考になればと思います。